Embedding Model
Embedding model components in Langflow generate text embeddings using a specified Large Language Model (LLM).
Langflow includes an Embedding Model core component that has built-in support for some LLMs. Alternatively, you can use any additional embedding model in place of the Embedding Model core component.
Use embedding model components in a flow
Use embedding model components anywhere you need to generate embeddings in a flow.
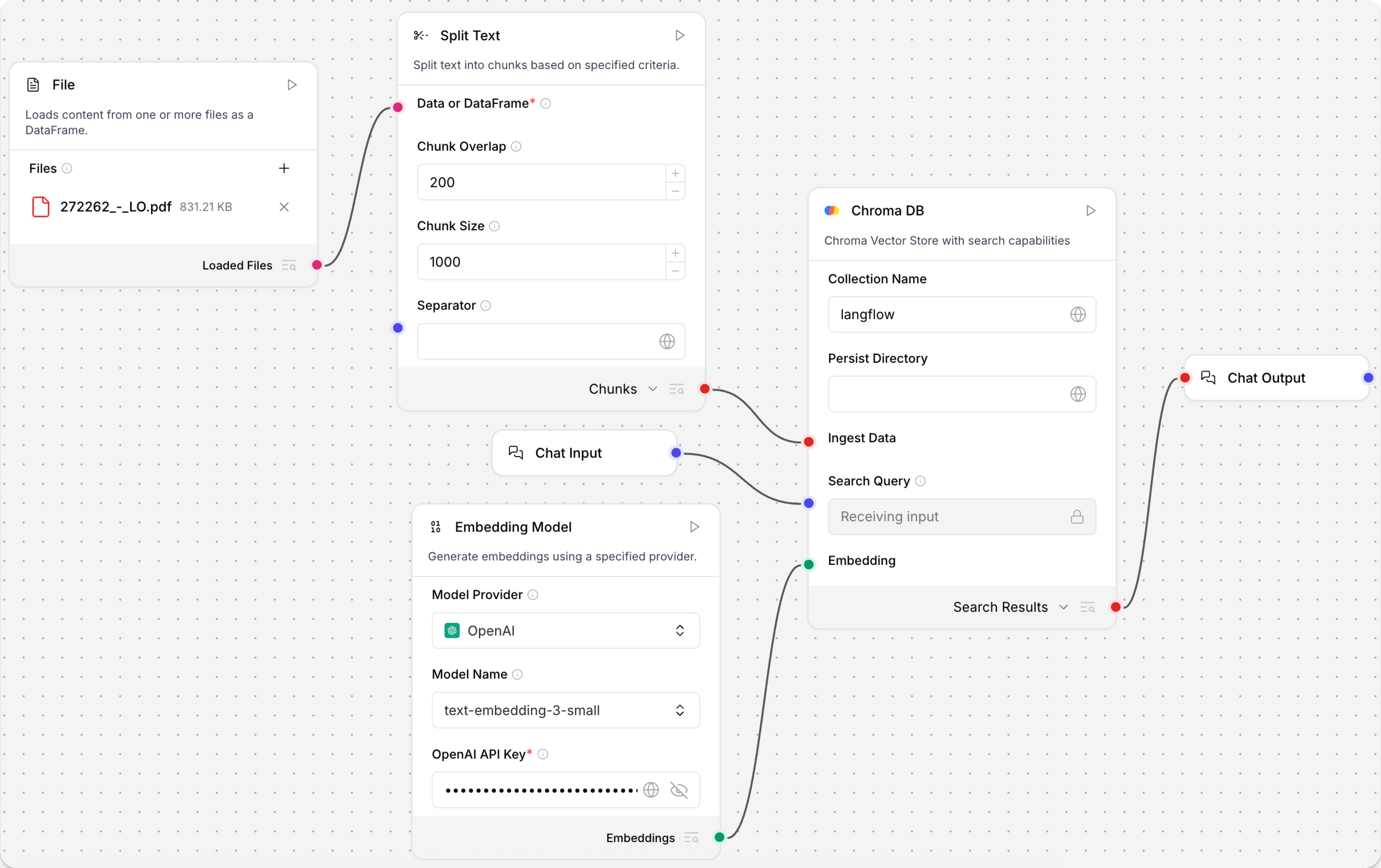
This example shows how to use an embedding model component in a flow to create a semantic search system. This flow loads a text file, splits the text into chunks, generates embeddings for each chunk, and then loads the chunks and embeddings into a vector store. The input and output components allow a user to query the vector store through a chat interface.
-
Create a flow, add a Read File component, and then select a file containing text data, such as a PDF, that you can use to test the flow.
-
To edit Langflow's global model provider configuration, do the following:
-
To open the Model Providers pane, click your profile icon, select Settings, and then click Model Providers.
-
In the Model Providers pane, select a provider.
-
In the API Key field, add your provider's API key. Some providers require additional configuration fields. For more information, see the model provider's documentation.
The key must have permission to call the models you want to use in your flow, and your account must have sufficient credits for the actions you want to perform.
You can only add one key for each provider. Make sure the key has access to all models that you want to use in Langflow.
-
Click Save.
-
Enable the specific models that you want to use in Langflow. The available models depend on the provider and your API key's permissions. Models that generate text are listed under Language Models. Models that generate embeddings are listed under Embedding Models.
After you enable a model in Langflow's global model configuration, you can use that model in any model-driven component in your flows.
My preferred provider or model isn't listedIf your preferred embedding model provider or model isn't available in Langflow's global Models, try one of these options:
- Configure the OpenAI Compatible provider to point at any OpenAI-compatible embeddings endpoint.
- Use any additional embedding models in place of the core component. Browse Bundles or Search for your preferred provider, such as the Hugging Face Embeddings Inference component.
-
-
Add the Embedding Model core component to your flow, and then select your configured embedding model from the Embedding Model dropdown.
-
Add a Split Text component to your flow. This component splits text input into smaller chunks to be processed into embeddings.
-
Add a vector store component, such as the Chroma DB component, to your flow, and then configure the component to connect to your vector database. This component stores the generated embeddings so they can be used for similarity search.
-
Connect the components:
- Connect the Read File component's Loaded Files output to the Split Text component's JSON or Table input.
- Connect the Split Text component's Chunks output to the vector store component's Ingest Data input.
- Connect the Embedding Model component's Embeddings output to the vector store component's Embedding input.
-
To query the vector store, add Chat Input and Output components:
- Connect the Chat Input component to the vector store component's Search Query input.
- Connect the vector store component's Search Results output to the Chat Output component.
-
Click Playground, and then enter a search query to retrieve text chunks that are most semantically similar to your query.
Embedding Model parameters
The following parameters are for the Embedding Model core component. Other embedding model components can have additional or different parameters.
Some parameters are hidden by default in the visual editor. You can modify all component parameters through the component inspection panel that appears when you select a component.
| Name | Display Name | Type | Description |
|---|---|---|---|
| provider | Model Provider | List | Input parameter. Select the embedding model provider. Models are configured globally in the Models pane. |
| model | Model Name | List | Input parameter. Select the embedding model to use. Options depend on the selected provider and are configured globally in the Models pane. |
| api_base | API Base URL | String | Input parameter. Base URL for the API. Leave empty for default. |
| dimensions | Dimensions | Integer | Input parameter. The number of dimensions for the output embeddings. |
| chunk_size | Chunk Size | Integer | Input parameter. The size of text chunks to process. Default: 1000. |
| request_timeout | Request Timeout | Float | Input parameter. Timeout for API requests. |
| max_retries | Max Retries | Integer | Input parameter. Maximum number of retry attempts. Default: 3. |
| show_progress_bar | Show Progress Bar | Boolean | Input parameter. Whether to display a progress bar during embedding generation. |
| model_kwargs | Model Kwargs | Dictionary | Input parameter. Additional keyword arguments to pass to the model. |
| embeddings | Embeddings | Embeddings | Output parameter. An instance for generating embeddings using the selected provider. |
Additional embedding models
If your provider or model isn't available in Langflow's global Models, you can replace the Embedding Model core component with any other component that generates embeddings.
To find additional embedding model components, browse Bundles or Search for your preferred provider.
Pair models with vector stores
By design, vector data is essential for LLM applications, such as chatbots and agents.
While you can use an LLM alone for generic chat interactions and common tasks, you can take your application to the next level with context sensitivity (such as RAG) and custom datasets (such as internal business data). This often requires integrating vector databases and vector searches that provide the additional context and define meaningful queries.
Langflow includes vector store components that can read and write vector data, including embedding storage, similarity search, Graph RAG traversals, and dedicated search instances like OpenSearch. Because of their interdependent functionality, it is common to use vector store, language model, and embedding model components in the same flow or in a series of dependent flows.
To find available vector store components, browse Bundles or Search for your preferred vector database provider.
Example: Vector search flow
For a tutorial that uses vector data in a flow, see Create a vector RAG chatbot.
The following example demonstrates how to use vector store components in flows alongside related components like embedding model and language model components. These steps walk through important configuration details, functionality, and best practices for using these components effectively. This is only one example; it isn't a prescriptive guide to all possible use cases or configurations.
-
Create a flow with the Vector Store RAG template.
This template has two subflows. The Load Data subflow loads embeddings and content into a vector database, and the Retriever subflow runs a vector search to retrieve relevant context based on a user's query.
-
Configure the database connection for both Astra DB components, or replace them with another pair of vector store components of your choice. Make sure the components connect to the same vector store, and that the component in the Retriever subflow is able to run a similarity search.
The parameters you set in each vector store component depend on the component's role in your flow. In this example, the Load Data subflow writes to the vector store, whereas the Retriever subflow reads from the vector store. Therefore, search-related parameters are only relevant to the Vector Search component in the Retriever subflow.
For information about specific parameters, see the documentation for your chosen vector store component.
-
To configure the embedding model, do one of the following:
-
Use an OpenAI model: In both OpenAI Embeddings components, enter your OpenAI API key. You can use the default model or select a different OpenAI embedding model.
-
Use another provider: Replace the OpenAI Embeddings components with another pair of embedding model components of your choice, and then configure the parameters and credentials accordingly.
-
Use Astra DB vectorize: If you are using an Astra DB vector store that has a vectorize integration, you can remove both OpenAI Embeddings components. If you do this, the vectorize integration automatically generates embeddings from the Ingest Data (in the Load Data subflow) and Search Query (in the Retriever subflow).
tipIf your vector store already contains embeddings, make sure your embedding model components use the same model as your previous embeddings. Mixing embedding models in the same vector store can produce inaccurate search results.
-
-
Recommended: In the Split Text component, optimize the chunking settings for your embedding model. For example, if your embedding model has a token limit of 512, then the Chunk Size parameter must not exceed that limit.
Additionally, because the Retriever subflow passes the chat input directly to the vector store component for vector search, make sure that your chat input string doesn't exceed your embedding model's limits. For this example, you can enter a query that is within the limits; however, in a production environment, you might need to implement additional checks or preprocessing steps to ensure compliance. For example, use additional components to prepare the chat input before running the vector search, or enforce chat input limits in your application code.
-
In the Language Model component, enter your OpenAI API key, or select a different provider and model to use for the chat portion of the flow.
-
Run the Load Data subflow to populate your vector store. In the Read File component, select one or more files, and then click Run component on the vector store component in the Load Data subflow.
The Load Data subflow loads files from your local machine, chunks them, generates embeddings for the chunks, and then stores the chunks and their embeddings in the vector database.
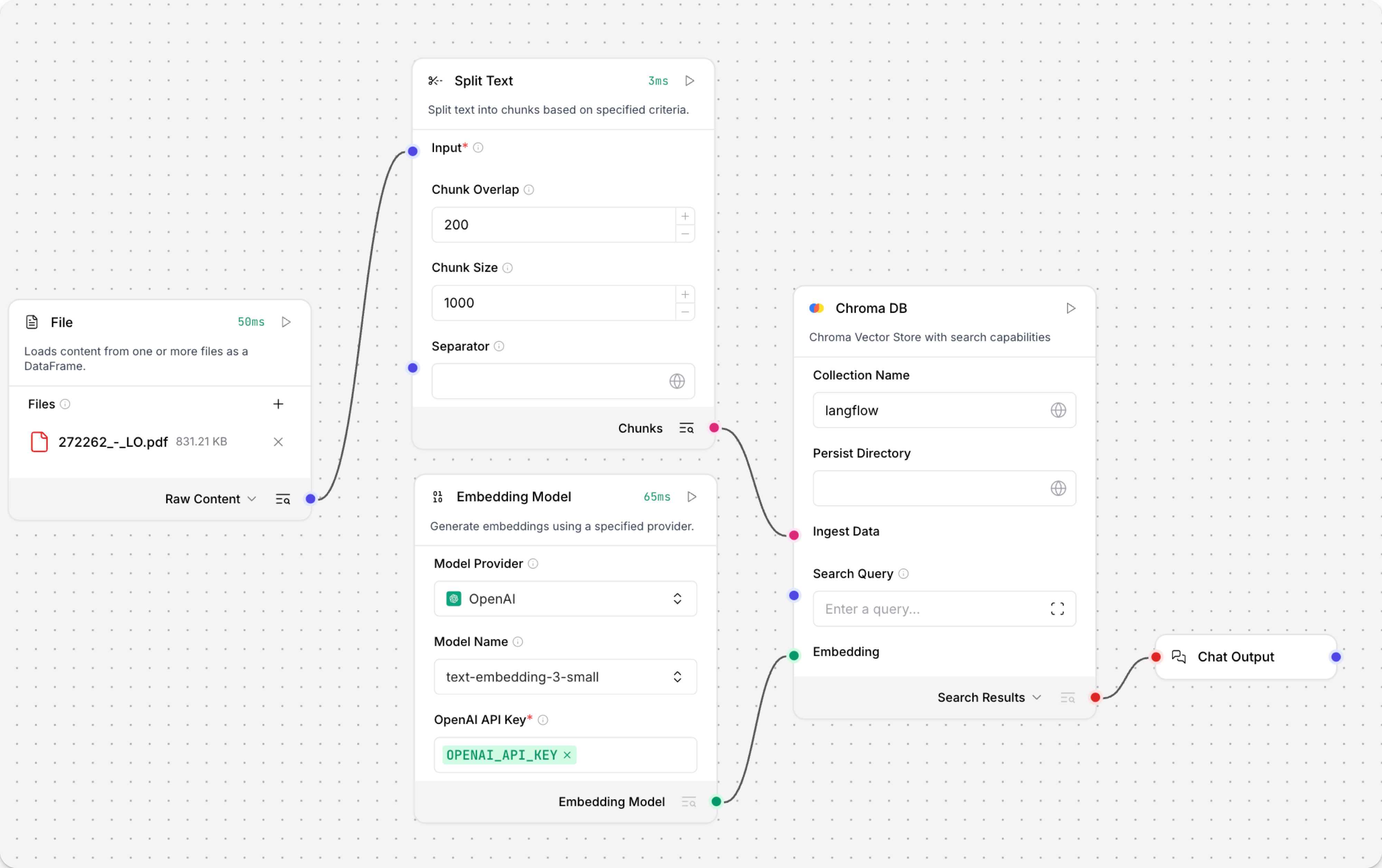
The Load Data subflow is separate from the Retriever subflow because you probably won't run it every time you use the chat. You can run the Load Data subflow as needed to preload or update the data in your vector store. Then, your chat interactions only use the components that are necessary for chat.
If your vector store already contains data that you want to use for vector search, then you don't need to run the Load Data subflow.
-
Open the Playground and start chatting to run the Retriever subflow.
The Retriever subflow generates an embedding from chat input, runs a vector search to retrieve similar content from your vector store, parses the search results into supplemental context for the LLM, and then uses the LLM to generate a natural language response to your query. The LLM uses the vector search results along with its internal training data and tools, such as basic web search and datetime information, to produce the response.
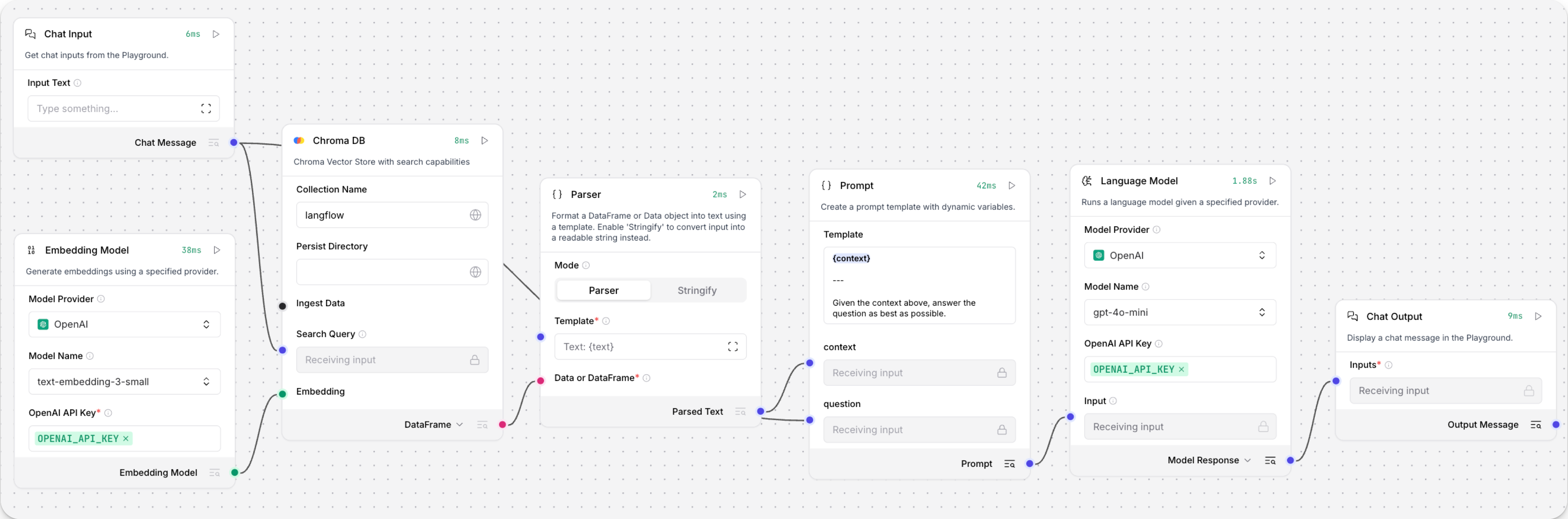
To avoid passing the entire block of raw search results to the LLM, the Parser component extracts
textstrings from the search resultsJSONobject, and then passes them to the Prompt Template component inMessageformat. From there, the strings and other template content are compiled into natural language instructions for the LLM.You can use other components for this transformation, such as the JSON Operations component, depending on how you want to use the search results.
To view the raw search results, click Inspect output on the vector store component after running the Retriever subflow.
Was this page helpful?