Create a vector RAG chatbot
This tutorial demonstrates how you can use Langflow to create a chatbot application that uses Retrieval Augmented Generation (RAG) to embed your data as vectors in a vector database, and then chat with the data.
Prerequisites
- Install and start Langflow
- Create a Langflow API key
- Create an OpenAI API key
- Install the Langflow JavaScript client
- Be familiar with vector search concepts and applications, such as vector databases and RAG
Create a vector RAG flow
-
In Langflow, click New Flow, and then select the Vector Store RAG template.
About the Vector Store RAG template
This template has two flows.
The Load Data Flow populates a vector store with data from a file. This data is used to respond to queries submitted to the Retriever Flow.
Specifically, the Load Data Flow ingests data from a local file, splits the data into chunks, loads and indexes the data in your vector database, and then computes embeddings for the chunks. The embeddings are also stored with the loaded data. This flow only needs to run when you need to load data into your vector database.
The Retriever Flow receives chat input, generates an embedding for the input, and then uses several components to reconstruct chunks into text and generate a response by comparing the new embedding to the stored embeddings to find similar data.
-
Add your OpenAI API key to both OpenAI Embeddings components.
-
Optional: Replace both Astra DB vector store components with a Chroma DB or another vector store component of your choice. This tutorial uses Chroma DB.
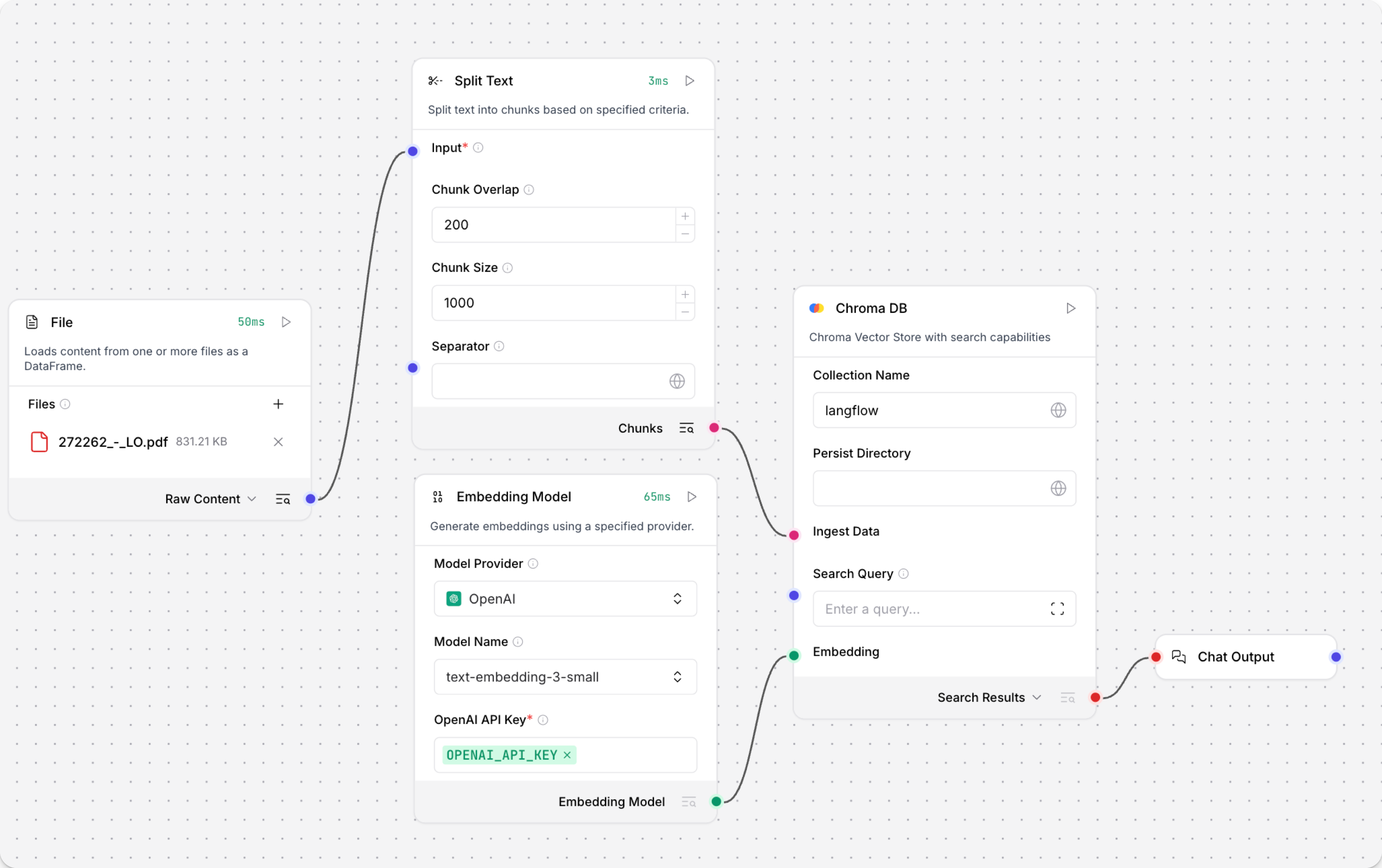
The Load Data Flow should have Read File, Split Text, Embedding Model, vector store (such as Chroma DB), and Chat Output components:
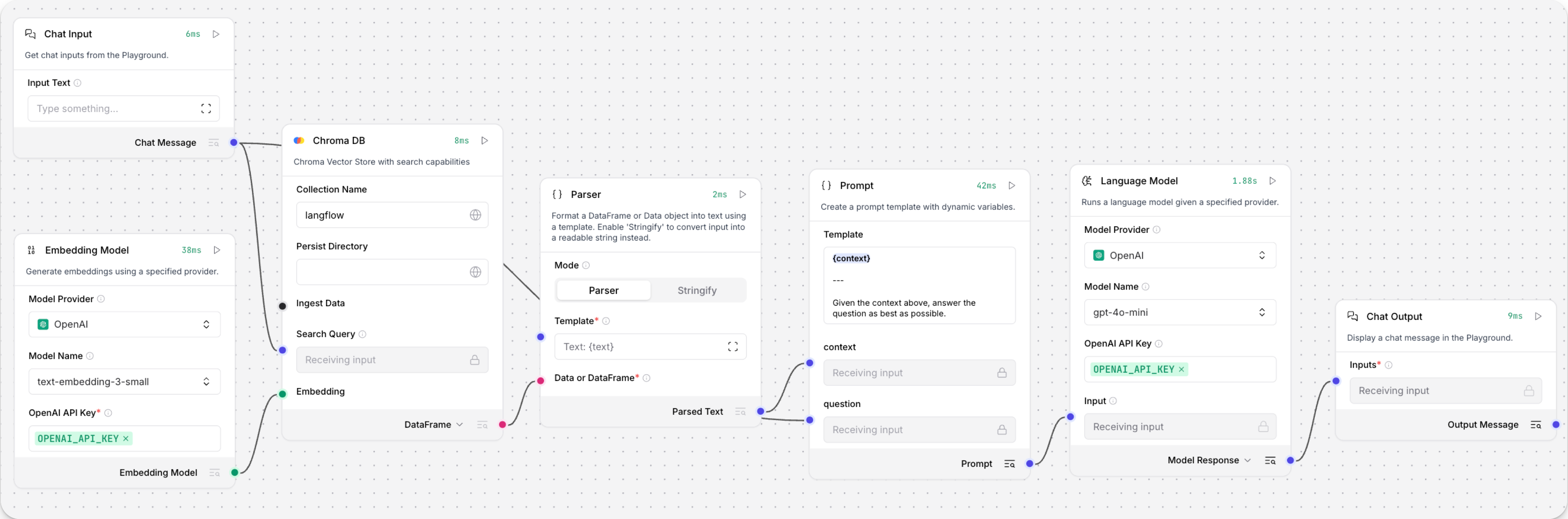
The Retriever Flow should have Chat Input, Embedding Model, vector store, Parser, Prompt, Language Model, and Chat Output components:
The flows are ready to use. Continue the tutorial to learn how to use the loading flow to load data into your vector store, and then call the chat flow in a chatbot application.
Load data and generate embeddings
To load data and generate embeddings, you can use the visual editor or the /v2/files endpoint.
The visual editor option is simpler, but it is only recommended for scenarios where the user who created the flow is the same user who loads data into the database.
In situations where many users load data or you need to load data programmatically, use the Langflow API option.
- Visual editor
- Langflow API
- In your RAG chatbot flow, click the Read File component, and then click File.
- Select the local file you want to upload, and then click Open. The file is loaded to your Langflow server.
- To load the data into your vector database, click the vector store component, and then click Run component to run the selected component and all prior dependent components.
To load data programmatically, use the /v2/files/ and /v1/run/$FLOW_ID endpoints. The first endpoint loads a file to your Langflow server, and then returns an uploaded file path. The second endpoint runs the Load Data Flow, referencing the uploaded file path, to chunk, embed, and load the data into the vector store.
For an example of constructing file upload requests in Python, see the Create a chatbot that can ingest files tutorial.
The following script demonstrates this process.
_37// Node 18+ example using global fetch, FormData, and Blob_37import fs from 'fs/promises';_37_37// 1. Prepare the form data with the file to upload_37const fileBuffer = await fs.readFile('FILE_NAME');_37const data = new FormData();_37data.append('file', new Blob([fileBuffer]), 'FILE_NAME');_37const headers = { 'x-api-key': 'LANGFLOW_API_KEY' };_37_37// 2. Upload the file to Langflow_37const uploadRes = await fetch('LANGFLOW_SERVER_ADDRESS/api/v2/files/', {_37 method: 'POST',_37 headers,_37 body: data_37});_37const uploadData = await uploadRes.json();_37const uploadedPath = uploadData.path;_37_37// 3. Call the Langflow run endpoint with the uploaded file path_37const payload = {_37 input_value: "Analyze this file",_37 output_type: "chat",_37 input_type: "text",_37 tweaks: {_37 'FILE_COMPONENT_NAME': {_37 path: uploadedPath_37 }_37 }_37};_37const runRes = await fetch('LANGFLOW_SERVER_ADDRESS/api/v1/run/FLOW_ID', {_37 method: 'POST',_37 headers: { 'Content-Type': 'application/json', 'x-api-key': 'LANGFLOW_API_KEY' },_37 body: JSON.stringify(payload)_37});_37const langflowData = await runRes.json();_37// Output only the message_37console.log(langflowData.outputs?.[0]?.outputs?.[0]?.results?.message?.data?.text);
When the flow runs, the flow ingests the selected file, chunks the data, loads the data into the vector store database, and then generates embeddings for the chunks, which are also stored in the vector store.
Your database now contains data with vector embeddings that an LLM can use as context to respond to queries, as demonstrated in the next section of the tutorial.
Chat with your flow from a JavaScript application
To chat with the data in your vector database, create a chatbot application that runs the Retriever Flow programmatically.
This tutorial uses JavaScript for demonstration purposes.
-
To construct the chatbot, gather the following information:
LANGFLOW_SERVER_ADDRESS: Your Langflow server's domain. The default value is127.0.0.1:7860. You can get this value from the code snippets on your flow's API access pane.FLOW_ID: Your flow's UUID or custom endpoint name. You can get this value from the code snippets on your flow's API access pane.LANGFLOW_API_KEY: A valid Langflow API key.
-
Copy the following script into a JavaScript file, and then replace the placeholders with the information you gathered in the previous step:
_50const readline = require('readline');_50const { LangflowClient } = require('@datastax/langflow-client');_50_50# pragma: allowlist nextline secret_50const API_KEY = 'LANGFLOW_API_KEY';_50const SERVER = 'LANGFLOW_SERVER_ADDRESS';_50const FLOW_ID = 'FLOW_ID';_50_50const rl = readline.createInterface({ input: process.stdin, output: process.stdout });_50_50// Initialize the Langflow client_50const client = new LangflowClient({_50baseUrl: SERVER,_50apiKey: API_KEY_50});_50_50async function sendMessage(message) {_50try {_50const response = await client.flow(FLOW_ID).run(message, {_50session_id: 'user_1'_50});_50_50// Use the convenience method to get the chat output text_50return response.chatOutputText() || 'No response';_50} catch (error) {_50return `Error: ${error.message}`;_50}_50}_50_50function chat() {_50console.log('🤖 Langflow RAG Chatbot (type "quit" to exit)\n');_50_50const ask = () => {_50rl.question('👤 You: ', async (input) => {_50if (['quit', 'exit', 'bye'].includes(input.trim().toLowerCase())) {_50console.log('👋 Goodbye!');_50rl.close();_50return;_50}_50_50const response = await sendMessage(input.trim());_50console.log(`🤖 Assistant: ${response}\n`);_50ask();_50});_50};_50_50ask();_50}_50_50chat();The script creates a Node application that chats with the content in your vector database, using the
chatinput and output types to communicate with your flow. Chat maintains ongoing conversation context across multiple messages. If you usedtexttype inputs and outputs, each request is a standalone text string.tipThe Langflow TypeScript client has a
chatOutputText()convenience method that simplifies working with Langflow's complex JSON response structure. Instead of manually navigating through multiple levels of nested objects withdata.outputs[0].outputs[0].results.message.data.text, the client automatically extracts the message text and handles potentially undefined values gracefully. -
Save and run the script to send the requests and test the flow.
Result
The following is an example response from this tutorial's flow. Due to the nature of LLMs and variations in your inputs, your response might be different.
_10👤 You: Do you have any documents about engines?_10🤖 Assistant: Yes, the provided text contains several warnings and guidelines related to engine installation, maintenance, and selection. It emphasizes the importance of using the correct engine for specific applications, ensuring all components are in good condition, and following safety precautions to prevent fire or explosion. If you need more specific information or details, please let me know!_10_10👤 You: It should be about a Briggs and Stratton engine._10🤖 Assistant: The text provides important safety and installation guidelines for Briggs & Stratton engines. It emphasizes that these engines should not be used on 3-wheel All-Terrain Vehicles (ATVs), motor bikes, aircraft products, or vehicles intended for competitive events, as such uses are not approved by Briggs & Stratton._10_10If you have any specific questions about Briggs & Stratton engines or need further information, feel free to ask!
Next steps
For more information on building or extending this tutorial, see the following: