Docling
Bundles contain custom components that support specific third-party integrations with Langflow.
Langflow integrates with Docling through a bundle of components for parsing and chunking documents.
Install the Docling bundle
The Docling bundle is included in the lfx-docling Extension bundle, which is installed automatically as part of uv pip install langflow.
If you need to install it separately, run:
_10uv pip install lfx-docling_10uv run langflow run
To verify the bundle is loaded in your environment:
_10lfx extension list
Optional extras
Some Docling components require additional dependencies that are not installed by default.
Local model (required for the Docling local model component):
_10uv pip install "lfx-docling[local]"
Alternatively, if you installed Langflow as a package:
_10uv pip install "langflow[docling]"
Chunking (HybridChunker and HierarchicalChunker support for the Chunk DoclingDocument component):
_10uv pip install "lfx-docling[chunking]"
Image description (vision model support for image-rich documents):
_10uv pip install "lfx-docling[image-description]"
Prerequisites
-
Enable Developer Mode for Windows:
If you are running Langflow Desktop on Windows, you must enable Developer Mode to use the Docling components. The location of this setting depends on your Windows OS version. Find For developers in your Windows Settings, or search for "Developer" in the Windows search bar, and then enable Developer mode. You might need to restart your computer or Langflow to apply the change.
-
Langflow Desktop: Set
LANGFLOW_DOCLING=Truein your.envfile to enable Docling dependency installation. For more information, see Set environment variables for Langflow Desktop. -
macOS Intel (x86_64): Use the Docling installation guide to install the Docling dependency.
- Docker/Linux system dependencies: If running Langflow in a Docker container on Linux, you might need to install additional system packages for document processing. For more information, see Document processing errors in Docker containers.
Use Docling components in a flow
To learn more about content extraction with Docling, see the video tutorial Docling + Langflow: Document Processing for AI Workflows.
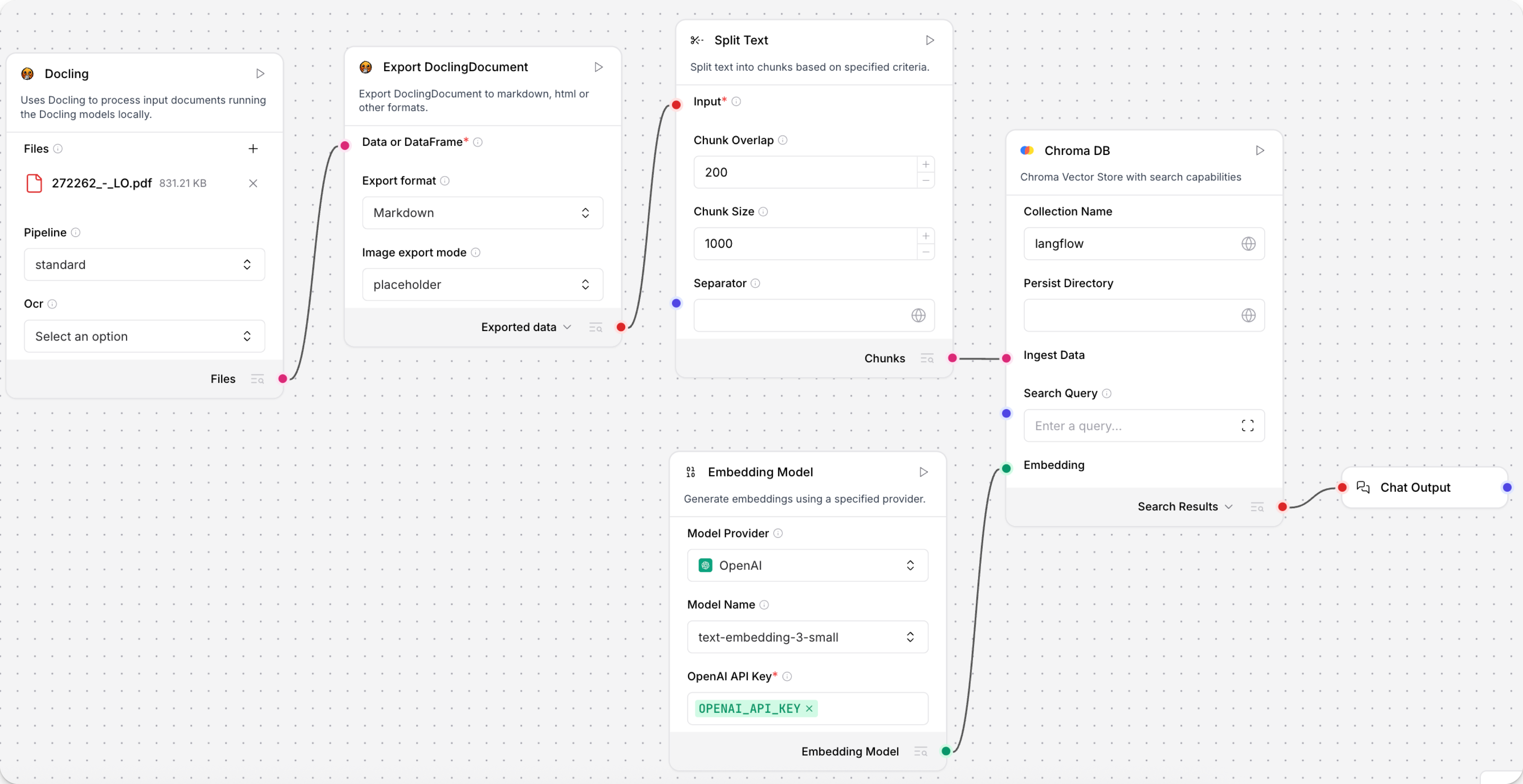
This example demonstrates how to use Docling components to split a PDF in a flow:
-
Connect a Docling and an Export DoclingDocument component to a Split Text component.
The Docling component loads the document, and the Export DoclingDocument component converts the
DoclingDocumentinto the format you select. This example converts the document to Markdown, with images represented as placeholders. The Split Text component will split the Markdown into chunks for the vector database to store in the next part of the flow. -
Connect a Chroma DB vector store component to the Split Text component's Chunks output.
-
Connect an embedding model component to the Chroma DB component's Embedding port and a Chat Output component to view the extracted
Table. -
In the embedding model component, select your preferred model, provide credentials, and configure other settings as needed.
-
Add a file to the Docling component.
-
To run the flow, click Playground.
The chunked document is loaded as vectors into your vector database.
Docling components
The following sections describe the purpose and configuration options for each component in the Docling bundle.
Docling local model
The Docling component ingests documents, and then uses Docling to process them by running a local Docling model.
It outputs files, which is the processed files with DoclingDocument data.
For more information, see the Docling IBM models project repository.
Docling parameters
| Name | Type | Description |
|---|---|---|
| files | File | The files to process. |
| pipeline | String | Docling pipeline to use (standard, vlm). |
| ocr_engine | String | OCR engine to use (easyocr, tesserocr, rapidocr, ocrmac). |
Docling Serve
The Docling Serve component ingests documents and processes them with a Docling API service rather than a local model.
It outputs files, which is the processed files with DoclingDocument data.
For more information, see the Docling serve project repository.
Docling Serve parameters
| Name | Type | Description |
|---|---|---|
| files | File | The files to process. |
| api_url | String | URL of the Docling Serve instance. |
| max_concurrency | Integer | Maximum number of concurrent requests for the server. |
| max_poll_timeout | Float | Maximum waiting time for the document conversion to complete. |
| api_headers | Dict | Optional dictionary of additional headers required for connecting to Docling Serve. |
| docling_serve_opts | Dict | Optional dictionary of additional options for Docling Serve. |
Chunk DoclingDocument
The Chunk DoclingDocument component splits DoclingDocument objects into chunks.
This component requires Docling's optional chunking dependencies.
It outputs the chunked documents as a Table.
For more information, see the Docling core project repository.
Chunk DoclingDocument parameters
| Name | Type | Description |
|---|---|---|
| data_inputs | JSON or Table | The data with documents to split in chunks. |
| chunker | String | Which chunker to use (HybridChunker, HierarchicalChunker). |
| provider | String | Which tokenizer provider (Hugging Face, OpenAI). |
| hf_model_name | String | Model name of the tokenizer to use with the HybridChunker when Hugging Face is chosen. |
| openai_model_name | String | Model name of the tokenizer to use with the HybridChunker when OpenAI is chosen. |
| max_tokens | Integer | Maximum number of tokens for the HybridChunker. |
| doc_key | String | The key to use for the DoclingDocument column. |
Export DoclingDocument
The Export DoclingDocument component exports DoclingDocument to Markdown, HTML, and other formats.
It can output the exported data as either JSON or Table.
For more information, see the Docling core project repository.
Export DoclingDocument parameters
| Name | Type | Description |
|---|---|---|
| data_inputs | JSON or Table | The data with documents to export. |
| export_format | String | Select the export format to convert the input (Markdown, HTML, Plaintext, DocTags). |
| image_mode | String | Specify how images are exported in the output (placeholder, embedded). |
| md_image_placeholder | String | Specify the image placeholder for markdown exports. |
| md_page_break_placeholder | String | Add this placeholder between pages in the markdown output. |
| doc_key | String | The key to use for the DoclingDocument column. |